Automated configuration management for non containerised workloads
Table of contents
- Introduction
- Term definitions
- Roles architecture
Introduction
In this article, we will present a flexible design that can be used when we have to manage the configuration of a diverse fleet of non-containerized workloads. This might seem a simple task, but it needs to be designed properly to avoid ending up with a patchwork of snowflake configurations.
We will use a relatively simple environment for demonstration purposes and define concepts that can be implemented both with Chef and SaltStack.
Term definitions
In order to ensure that everyone is on the same page when reading through the document, I will define here a few basic concepts that will be used throughout the document.
These concepts might be defined differently across different organisations, so in order to avoid confusion, we will define them here as well so everyone can quickly refer to them if needed.
Idempotency
What is idempotency:
Idempotency is a property of an operation where given the same input, doing it once or many times has the same effect on the system. If our system is already in the desired state then nothing happnes
Idempotent operations
Some operations are naturally idempotent.
For example, if we have a list of users that needs to be created and an automated operation that creates the users, if the users already exist, then repeating the operation will do nothing.
If one of the users is missing, then they will be created. If one of the users has been modified manually, then they will be reverted back to the official settings.
Non-idempotent operations
Some operations are naturally non-idempotent.
For example, when applying patches and updates to a system.
Let’s assume we have a Debian-based system. If we execute apt-get update && apt-get upgrade today and tomorrow, we may get different results even though we use the same input (repos) to the program apt-get.
The reason for this is that between these two days, the actual content of the repos has changed since new packages have been added. This is expected and natural. This operation is by default non-idempotent.
Converting a non-idempotent operation to idempotent
When managing a large fleet of systems, we should make sure all of our automated operations are idempotent. As we explained earlier, some operations are naturally non-idempotent, so how do we ensure that these operations are converted to idempotent ones?
In our particular example, we can convert our apt-get execution from non-idempotent to idempotent by providing our own package repos that are going to use snapshots of the official repos. These snapshots are frozen in time and ensure all of our systems will be using the same versions.
Whenever we want to roll out updates, we can create a new snapshot, apply our patches, and so on.
System role
A system role is a classification or label assigned to a system. It is usually related to a function the system has to perform, but it can also be related to an operation that will be performed on a system. Roles are natively supported by both Chef and SaltStack.
According to Chef:
A role is a way to define certain patterns and processes that exist across nodes in an organization as belonging to a single job function. Each role consists of zero (or more) attributes and a run-list. Each node can have zero (or more) roles assigned to it. When a role is run against a node, the configuration details of that node are compared against the attributes of the role, and then the contents of that role’s run-list are applied to the node’s configuration details. When a Chef Infra Client runs, it merges its own attributes and run-lists with those contained within each assigned role.
And for SaltStack:
A SaltStack minion role is a custom label or classification assigned to a Salt minion, typically implemented as a grain (a piece of minion-specific data). Roles group minions by function, such as “webserver” or “database,” enabling targeted state application, targeting in commands, and environment-specific configurations. They are often set via pillar data, external node classifiers, or directly in minion configs.
By combining idempotent operations in roles, we can create functional definitions for our systems. These can be related to the purpose of each system or to specific operations that will be performed on a specific system.
Role components
Chef cookbooks
In the Chef world, the content of a role comes in the form of a run-list. Run-lists can contain recipes or collections of recipes such as cookbooks.
According to Chef documentation, a cookbook is:
A cookbook is the fundamental unit of configuration and policy distribution in Chef Infra. A cookbook defines a scenario and contains everything that’s required to support that scenario:
- Recipes that specify which Chef Infra built-in resources to use, as well as the order in which they’re to be applied
- Attribute values, which allow environment-based configurations such as dev or production.
- Custom resources for extending Chef Infra beyond the built-in resources.
- Files and templates for distributing information to systems.
- Custom Ohai plugins for extending system configuration collection beyond the Ohai defaults.
- The metadata.rb file, which describes the cookbook itself and any dependencies it may have.
SaltStack formulas
In the SaltStack world, the content of a role can be a list of states, a list of apps, or a list of formulas.
Formulas are:
Formulas are pre-written Salt States. They are as open-ended as Salt States themselves and can be used for tasks such as installing a package, configuring and starting a service, setting up users or permissions, and many other common tasks.
Roles composability and versioning
Two key concepts of roles are composability and versioning.
Roles are composable, so a role can contain other roles. This will allow us to use roles as the building blocks of our infrastructure.
In order to use roles efficiently and effectively, roles and their components need to support versioning. This is what will allow us to test role changes in isolation and promote each version when it has been thoroughly tested without risking affecting any production services.
It also allows us to support multiple major releases if required by a customer.
For example, let’s assume that two customers have purchased our product and we have a support contract for both. But they have purchased different versions, and we need to provide hotfixes for both. How do we support both with our configuration automation system?
The answer is role versioning and version pinning.
Both customers will use the same roles, but they will use different versions.
This means that all cookbooks and SaltStack formulas will also have to support versioning, which means that they will have to live in different repos, have their own versioning schema, and ideally their own tests using kitchen-test, and their own CI/CD pipeline and quality criteria.
Salt stack roles versioning
SaltStack roles lack built-in versioning, so instead we need to use formulas in combination with role versions stored in pillars.
For example, we can define a role version in a pillar like so:
roles:
webserver:
version: 2.1.0
and then reference it in a state:
nginx:
pkg.installed:
- version:
- require:
- sls: common
this allows us to override it at runtime:
salt '*' state.apply webserver pillar='{"roles": {"webserver": {"version": "2.2.0"}}}'
We can also define formulas versions and use them in states like so:
# Deploy the stable master branch unless version overridden by passing
# Pillar at the CLI or via the Reactor.
deploy_myapp:
git.latest:
- name: [email protected]/myco/myapp.git
- version:
Highstate systems
In configuration management automation, we can generally identify two architectures.
Pull-based systems, systems where the actual nodes of a fleet will connect to a central point of reference and try to pull a definition of their state. These systems are Chef, Puppet, and SaltStack.
Push-based systems, systems where the central point of reference will push the desired state to the fleet. This is the model Ansible uses.
In the last few years, most of these systems have introduced additional features that allow a push system to act as a pull system and vice versa. There are merits in both architectures, and that is why every tool is trying to provide an implementation of both architectures.
The systems implementing the pull architecture can also be named highstate systems.
These systems are designed to connect regularly (usually every few minutes) to their configuration center and request their desired state, then apply this state to themselves. This means that if someone modifies something manually on the system, it will be reverted in the next convergence cycle.
This is a very powerful pattern and allows us to have consistent and compliant configurations across fleets of thousands of systems, but it also has some side effects that we will explore in the next sections. When we use a highstate configuration management system, we can use it in a number of different ways.
Fully managed systems
A fully managed system is a system whose configuration is fully automated. This type of system is quite expensive to maintain, since every single change to it will have to go through the full development lifecycle of its configuration management.
Let’s assume that we want to change a word in a configuration file of our system. This file is part of a Salt pillar that belongs to a formula or a recipe that belongs to a cookbook. After changing the word, we need to raise a merge request, which will be reviewed and merged.
After it’s merged, we will have CI tests executed on the cookbook/formula to make sure our change does not break the functionality, and if everything is OK, we will be able to release a new version, which will in turn find its way to our artifact repository ready to be deployed on the systems.
After the new version is available, we need to update our role definitions and release a new version for the role that will contain the new version of the cookbook/formula. Then we can start rolling this out to our systems.
That is a lot of work for a simple change, and imagine if we have a lot of changes like this.
Because of the cost and complexity, it makes sense to adopt the pattern of a fully managed system for systems with high complexity that are deployed at scale. When we have these two conditions, the cost of using any other automated or manual management practice is even higher than having a fully managed system.
Partially managed systems
A partially managed system is a system whose configuration is partially automated. This type of system can have its basic configuration fully automated but can also have some aspects that are not managed by our configuration management system.
These aspects can be managed either manually or by using other batch processing software such as Rundeck. Systems like these are usually application servers that do not have a huge number of deployments.
For example, let’s assume we have a highly available solution for Bitbucket. We can use our SaltStack/Chef automation to manage everything except the updates of the Bitbucket service itself. So we do user/access management, telemetry, and log shipping using Chef/SaltStack, but we do not touch the Bitbucket service itself.
The upgrades of this service are done every quarter, and they are automated using a batch job that will take a backup, do the update, and restore configuration.
This way, we have a system that is always compliant and, at the same time, allows us to do application upgrades according to our own schedule.
Another application of this pattern is if we have systems where configuration has to change often and during runtime. Let’s say we have a system that is doing firewalling and the rules of the firewall have to change several times per day and on short notice.
Again, we can have everything managed by Chef/SaltStack except the firewall. This can be automated by hooking up the firewall rule changes to a real-time configuration system that follows the needs of our customers.
Again, we get the best of both worlds: consistent configuration across our fleet while allowing for runtime firewall configuration according to our customer needs.
Heartbeat role
Now that all the necessary concepts have been defined, we can introduce the concept of the heartbeat role. The heartbeat role is the absolute minimum role any system in our fleet can have. In order for a system to be added to our fleet, it needs to have the heartbeat role.
This means three things:
- The heartbeat role must be very small. Its content can be (non-exhaustive list):
- User access (LDAP, SSO, etc.)
- Break-glass mechanism deployment
- Telemetry, log shipping, etc.
- Log rotation, housekeeping
- Access whitelisting
- Certificates, keys deployment
- Compliance rules
- The heartbeat role must always converge. If it breaks, then all systems break.
- The heartbeat role must be included in all other roles.
When we have defined a heartbeat role like this and use a highstate configuration management system, it means we have consistent deployment across the fleet. We have the same level of telemetry, user access, and housekeeping everywhere, and we do not have any diverging systems.
In the next section, we will explain how we can use all the concepts introduced so far to support a variety of workloads while at the same time remaining compliant and consistent, with no configuration sprawl.
Roles architecture
As we explained earlier, roles are composable, so we can have roles containing versions of roles. In this section, we will provide an example of how we can use the concepts introduced so far across a variety of systems while maintaining compliance and configuration consistency.
Our example environment will consist of the following roles:
- A bastion system
- Two Nginx servers, one for staging and one for production with different role versions assigned to them
- A new system that does not have an application role assigned to it yet
We can see all of these in the following diagram:
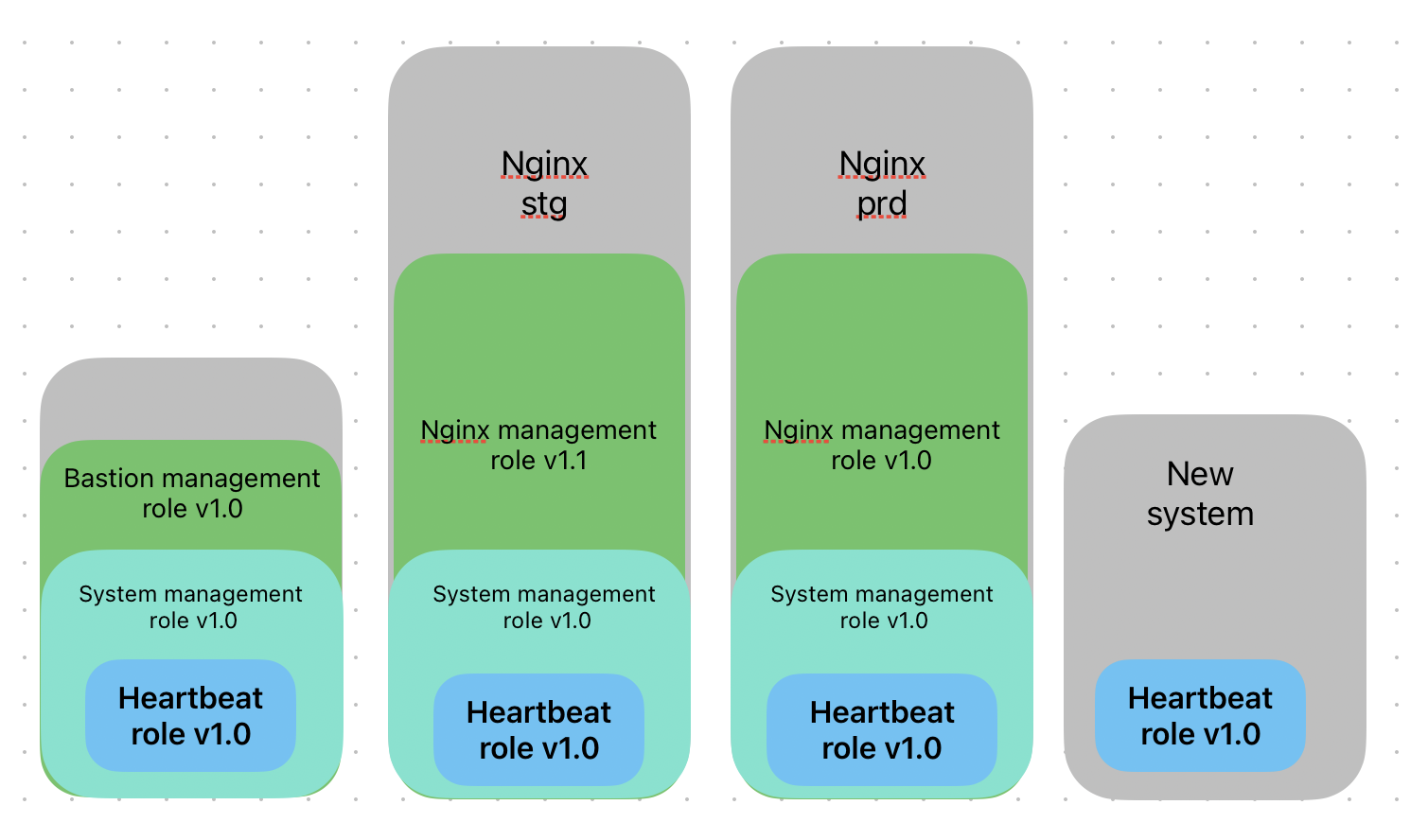
We can see our four systems.
Bastion
We have our bastion, which is a system that allows us to access other systems. It has only the bastion role, which includes the system management role and the heartbeat role.
The bastion role takes care of everything a bastion system needs to do.
The system management role is responsible for system management, including patching, and the heartbeat role is defined in the previous section.
New system
We have a new system that has no application role assigned to it, but because it has the heartbeat role attached to it, we have full access to it and telemetry from it.
Nginx staging
We have two Nginx systems with the Nginx role attached to them, a role that also includes the system management role and heartbeat role.
These two systems differ because the staging Nginx is running a newer version of the Nginx role as part of our testing.
After testing is completed, this version will be deployed to production.
Nginx production
In the meantime, the production Nginx is running the stable version of the Nginx role, which also includes the same versions of the system management and heartbeat roles as staging.
This way, we ensure consistency and compliance across the board without running the risk of affecting a production service while testing our new version of the role in staging.